Cet article présente une solution pour synchroniser le mouvement de la bouche d’un robot humanoïde avec sa voix. Le traitement du son se fera en temps réel sur une source non amplifiée : sortie PC, téléphone, tablette…
L’objectif est l’asservissement d’un servomoteur actionnant l’ouverture/fermeture sur l’axe vertical de la bouche. Ce mouvement est très simplifié par rapport aux mouvements des lèvres/mâchoires… Pour plus de réalisme il faudrait aussi reconnaître les phonèmes pour mimer la manière dont elles sont prononcées en tenant compte aussi de la langue parlé (anglais, français etc…).
Ceci est en dehors de notre sujet, nous nous contenterons ici d’un effet proche de ceux que produisent les marionnettistes et ventriloques en animation avec leur main.
Télécharger le code Arduino InMoov mouth synchro
De nombreux jouets simulent le mouvement de bouche, je n’ai pas eu à chercher longtemps pour retrouver dans les jouets des enfants une Barbie avec prise jack pour raccordement audio dont j’ai eu un instant l’espoir de récupérer le circuit … mais hélas la synchro ne fonctionne proprement que sur les deux ou trois phrases préenregistrées.
Ce type de jouet a probablement en mémoire les mouvements à réaliser évitant ainsi tout traitement du signal. Dommage…, mais au moins Barbie a eu la vie sauve 🙂
Principe retenu
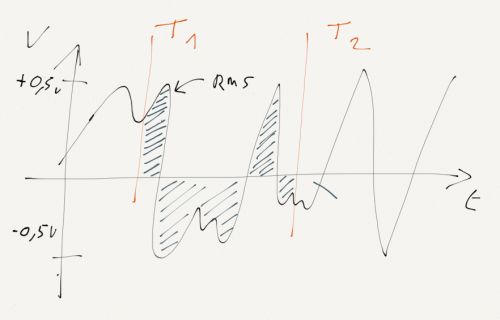
Un signal audio vocal oscille entre des valeurs négatives et positives avec une amplitude plus ou moins haute. Pour asservir le servo moteur nous allons calculer la puissance efficace (en watts) du signal aussi appelé RMS (en anglais Root Mean Square) afin de donner plus ou moins d’amplitude à l’ouverture de la mâchoire en fonction de la force de la voix. Le système s’auto-calibrera avec une position bouche fermée et servo moteur déconnecté lorsque aucun son n’est émis.
Je vous livre la formule de calcul du RMS pour une fonction sur un intervalle compris entre T1 et T2.
Avec f(t) notre signal audio échantillonné et (T1-T2) la durée de notre échantillonnage.
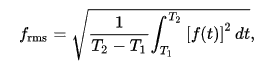
Quelques rappels sur la voix :
La voix a une fréquence comprise entre 800 hz et 3 kilos Hz (l’oreille humaine perçoit les fréquences jusqu’à 20 khz).
Le signal audio en sortie d’un pc est assez faible généralement situé entre –0.5 et + 0.5v, et doit être amplifié en cas de sortie sur des hauts parleurs externes.
La fréquence minimum pour numériser un signal doit être le double de celle du signal pour ne pas avoir de perte (théorème d’échantillonnage Nyquist–Shannon), sur un CD aussi le son est échantillonné à 44,1 kHz sur 16 bits.
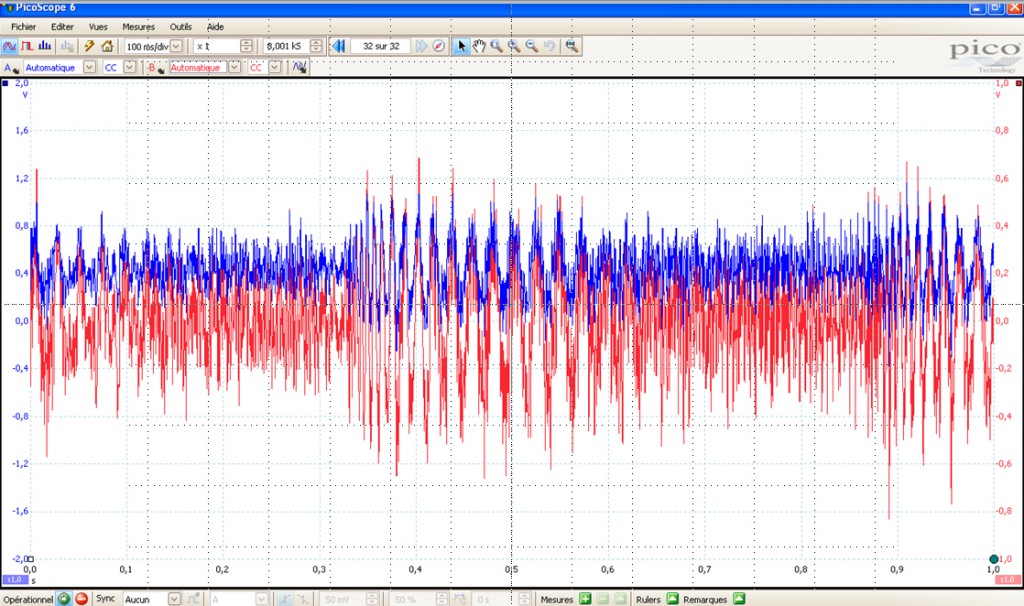 Visualisation du signal Audio en entrée (rouge) et après offset de 0.5V prêt pour numérisation
Visualisation du signal Audio en entrée (rouge) et après offset de 0.5V prêt pour numérisation

Notre objectif étant de réaliser ce système sur une base d’Arduino Uno, nous savons que les entrées analogiques (A0-A5) de l’arduino mesurent une tension entre 0 et 5v sur 10 bits soit 1024 valeurs.
Si, nous échantillonnons le signal audio en l’état la partie négative sera assimilé à 0v, on ne mesurera donc que la moitié du signal et d’autre part la précision de la mesure sur la base de la référence à 5 volts ne sera que de (1024 x 0.5)/5 = 102 valeurs possibles !
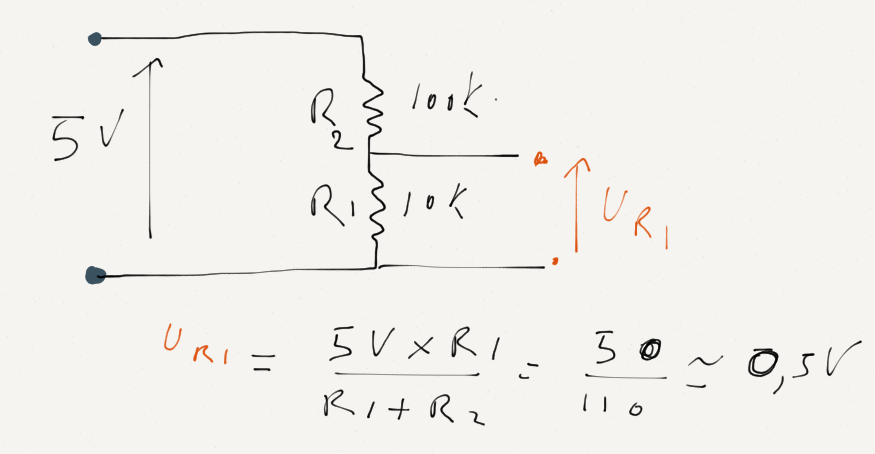
Pour ramener notre signal compris entre -0.5 et 0.5v à un signal entre 0 et 1 volts, il faut ajouter un offset de + 0.5Volts. Pour ce faire 2 résistances montées en pont diviseur feront l’affaire, le 0.5v correspond à 1/10 de la tension de référence 5 volt disponible sur l’arduino, le rapport de nos 2 résistances doit donc grosso modo être dans un rapport de 1 à 10.
R1 = 10ko (marron- noir – orange)
R2 = 100 ko (marron – noir – jaune)
Pour mémoire Ur1 =U x R1 / (R1 + R2) = (5 x 10 000 ) / (100 000 + 10 000) = 0.45 Volts
Un condensateur de valeur assez élevé (1 à 10 micro Farad) permettra de bloquer le retour des tensions continues (condensateur polarisé peu importe le sens).
Pour gagner en précision, le comparateur interne de l’ATmega328 nous permet de changer la tension de référence de son comparateur (soit externe pin AREF) ou bien possibilité de se caler sur une tension interne de 1.1 volts avec l’instruction > analogReference(INTERNAL), idéal pour notre besoin.
Schéma câblage
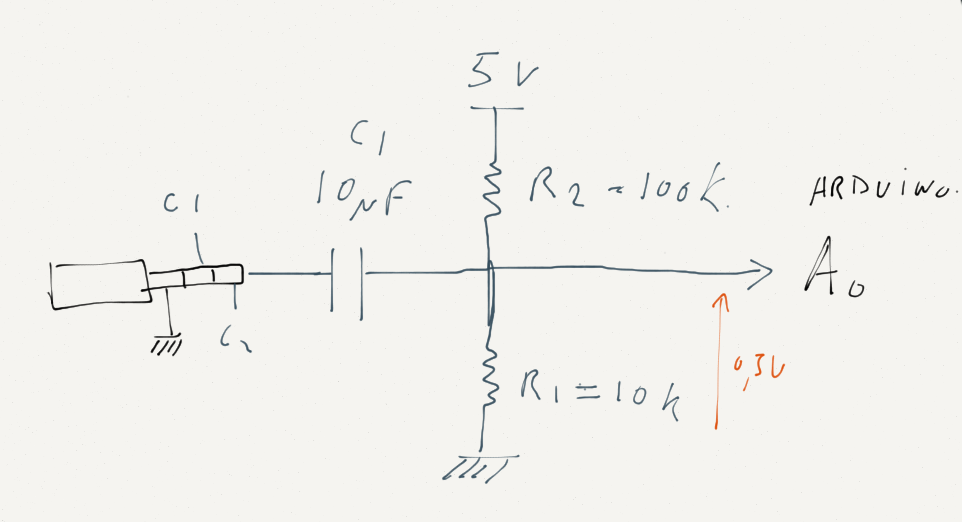
J’ai utilisé un des canaux audio pour l’échantillonnage, l’autre canal est relié à l’amplificateur.
(Suppose d’avoir la sortie voix doublée sur les 2 canaux audio)

Le programme :
Il présentes quelques optimisations :
la lecture de la valeur sur A0 se fait en manipulant les registres de l’ATmega, (équivalent à AnalogRead mais beaucoup plus rapide).
On gagne aussi en vitesse et capacité de stockage en se contentant d’une valeur sur 8 bits au lieu de 10 ( les 2 bits les moins significatif dit de poids faibles sont donc ignorés). On est sur une précision de 256 valeurs comprises entre 0 et 1.1Volts.
void AcquireData() {
_lastTime = micros();
for(uint16_t i=0;i<_samples;i++) {
while ((micros() - _lastTime) < _interval);
_vData[i]=ADCRead();
_lastTime+=_interval;
}
}
Merci à Didier pour ce code à retrouver sur Arduinoos
Pour le calcul du RMS, on utilise la valeur absolue pour gagner en temps de calcul plutôt que d’effectuer un passage au carré suivi de la racine carré…
uint16_t ComputeRMS() {
// compute average
uint32_t average=0;
for(uint16_t i=0;i<_samples;i++) {
average+=_vData[i];
}
average/=_samples;
//compute pseudo rms
uint32_t rms=0;
for(uint16_t i=0;i<_samples;i++) {
if (_vData[i]>=average) {
rms+=(_vData[i]-average);
} else {
rms+=(average-_vData[i]);
}
rms= ((rms * 500) / _samples);
// keep min / max for RMS value (needed to map on servo angle)
rmsMax=max(rms,rmsMax);
rmsMin=min(rms,rmsMin);
return(rms);
}
}
Vous pouvez jouer sur les paramètres fréquence d’échantillonnage et nombre d’échantillons pris pour le calcul du rms.
Je trouve qu’un bon compromis vitesse de traitement/précision est avons obtenu en échantillonnant à 8 kilos avec une fenêtre de 64 échantillons.
Ces traitements prennent environ 9 ms : durée d’échantillonnage + calcul du rms + traduction en valeur angulaire.
Durée d’échantillonnage : 64 x (1/8000) = 0.008 soit 8 ms
Le signal PWM envoyé au servo moteur a une fréquence de 50hz soit une période de 20ms à ajouter au temps de réponse nécessaire au déplacement du servo (quelques millisecondes)
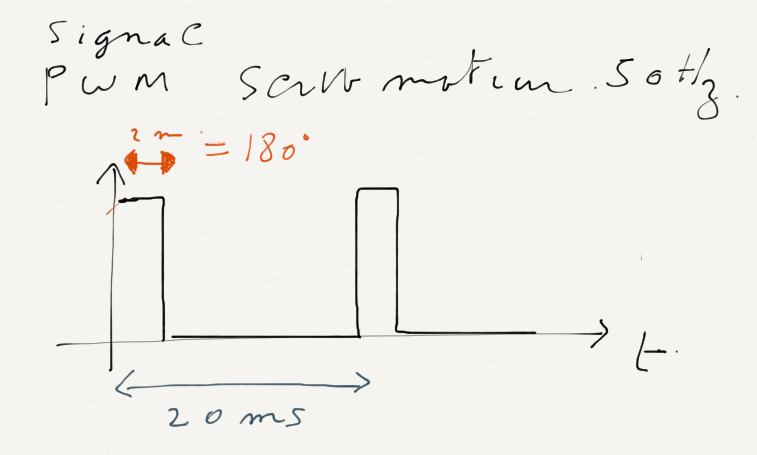
Cela induit un décalage temporel d’une trentaine de millisecondes entre le son émis et le mouvement de la bouche.
Quand l’audio et le visuel ne correspondent pas exactement, notre cerveau s’adapte et autorise jusqu’à un certain décalage. Cette fusion des deux stimuli malgré leur incohérence s’appelle l’effet de ventriloquisme dit « temporel » quand il y a un léger décalage entre le moment où on voit l’image et le moment où on entend le son, le cerveau va synchroniser le son avec l’image.
En général, le cerveau est moins sensible à l’asynchronie quand la vision précède l’audition, pas de chance… dans notre cas c’est l’inverse qui se produit…
Deux améliorations à apporter
1 – Ajout d’un filtre passe bande pour éliminer les bruits de fond, musiques, parasites.
2 – Ajout d’une ligne à retard sur la piste audio amplifiée pour compenser le temps de traitement du signal audio.
Matériel :
- une carte Arduino dédiée à l’analyse de la voix et au pilotage d’un servo moteur.
- Un servo moteur
- Un condensateur de 1 à 10 micro Farads
- Une résistance de 100k
- Une résistance de 10k
- Fiches jack/rca etc…
Quelques liens utiles :
Animatronic Mouths : http://www.pyroelectro.com/tutorials/animatronic_mouths
Logiciel spécialisé dans la création d’animation sur vidéo : http://mamoworld.com/tools/auto-lip-sync
Le datasheet de l’ATmega 328: http://www.atmel.com/images/Atmel-8271-8-bit-AVR-Microcontroller-ATmega48A-48PA-88A-88PA-168A-168PA-328-328P_datasheet_Complete.pdf
Mémoire décalage temporel interaural : http://www.uclouvain.be/cps/ucl/doc/commission-gbio/documents/memoire_DR.pdf